从零开始的 Python AsyncIO 生活

一直在用 AsyncIO在 Python里使用异步编程,但是从来没想过为什么,借这个机会浅浅搞一搞 AsyncIO
可迭代对象(Iterable)
首先,我们要明确什么是 Iterable,简而言之,就是可以放到 for 循环中的对象。常见的 list, str, tuple 以及 dict 等都是 Iterable
Python 是如何判断一个 obj 是不是 Iterable 的呢?我们可以使用 dir() 函数来查看它的属性列表。
使用下面这段代码,我们可以知道它们的共同接口
from typing import Iterable
iterable = [
"", # str
[], # list
{}, # dict
(), # tuple
set() # set
]
def show_diff(*objects: Iterable):
""" 打印 Iterable 和 object 的属性差集 """
assert objects
attrs = set(dir(objects[0]))
for obj in objects[1:]:
attrs &= set(dir(obj)) # 取 Iterable 交集
attrs -= set(dir(object)) # 取 Iterable 和 object 的差集
print(attrs)
show_diff(*iterable)
# {'__iter__', '__contains__', '__len__'}
可以看到,关键显然是 __iter__。事实上,对于任意指定了 __iter__ 方法的对象,都会被算作 Iterable。而 __len__ 和 __contains__ 等等,则是 容器 类型的 Iterable 的共有属性。
如果我们添加一个 非容器 类型的 Iterable,结果就显而易见了。
iterable = [
"", # str
[], # list
{}, # dict
(), # tuple
set(), # set
open(__file__) # IO
]
show_diff(*iterable)
# {'__iter__'}
迭代器(Iterator)
在 Python 中,诸如 __iter__ 这样的魔术方法都有相对应的调用方法,也就是 iter()
我们不妨来看一下上文所列举的 容器 型的 Iterable 在调用 iter() 后的结果
IO 类型相对特殊,暂时不作考虑。
for i in iterable:
print(iter(i))
"""
<str_iterator object at 0x7f7bd06fafe0>
<list_iterator object at 0x7f7bd06fafe0>
<dict_keyiterator object at 0x7f7bd08c4b80>
<tuple_iterator object at 0x7f7bd06fafe0>
<set_iterator object at 0x7f7bd0720440>
"""
可以看到,它们都返回了 Iterator 的对象。正如在 Iterable 中展示的那样,我们再次获取它们的属性差集。
# {'__next__', '__iter__'}
可以看到,相比于 Iterable 多了一个 __next__ 方法,从名字也能看出来,这便是用于在下一次迭代中返回数据的接口。
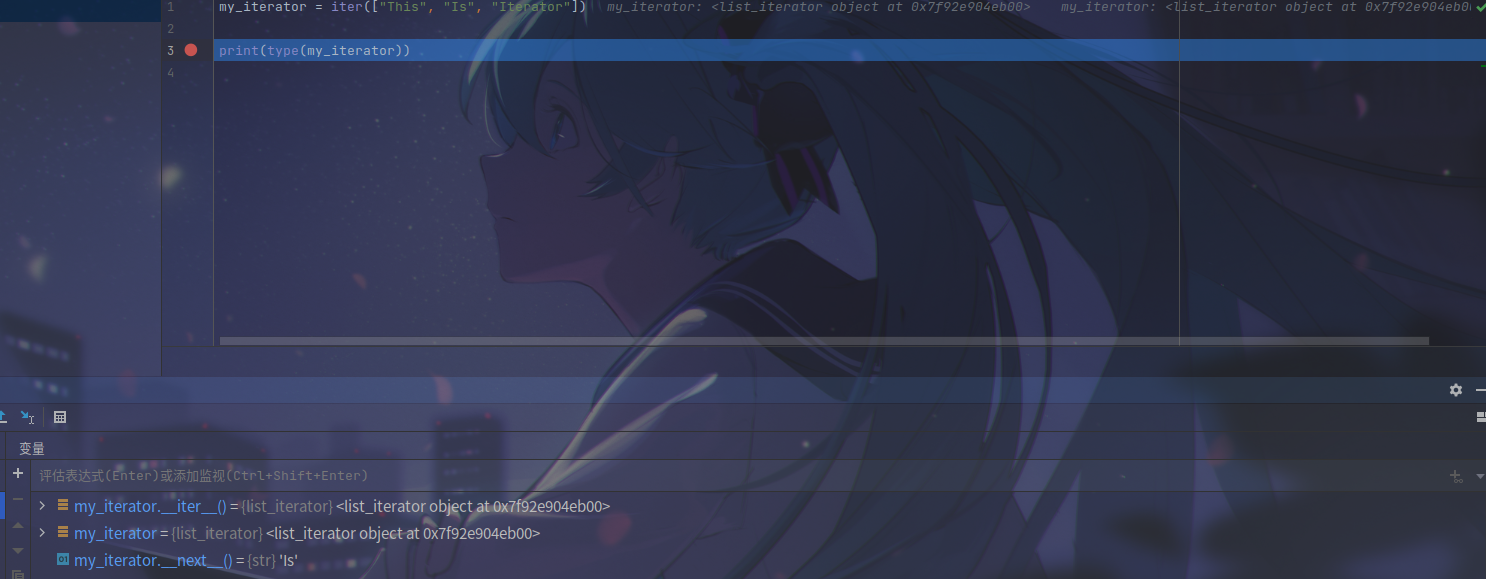
我们下断点查看,发现 list_iterator 的 __iter__ 显然是返回了它本身,而 __next__ 则会返回数据(在这里应该是 'This',但由于它再运行了一次 __iter__ 所以变成了下一个 `'Is')
在所有值迭代完毕后,它会抛出一个 StopIteration 的错误来告知迭代结束。
我们可以用下面的代码构建一个自定义的迭代器。
class MyIterator:
def __init__(self, Iter):
self.index = 0
self.data = Iter
def __next__(self):
while self.index < len(self.data):
data = self.data[self.index]
self.index += 1
return data
raise StopIteration
def __iter__(self):
""" 迭代器必须是可迭代的 """
return self
things = ["I", "AM", "ITERABLE", "GOD"]
for i in MyIterator(things): # -> i = iter(MyIterator(things)) && i = next(i)
print(i)
二者之间
回到我们最开始的 Iterable,我们说有 非容器 型的 Iterable,事实上,这些就是直接构建了我们的 Iterator
容器 型的 Iterable 是可重复迭代的(因为它们的 __iter__ 方法生成了新的 Iterator!),静态的。而 Iterator 则是一次性,可动态生成的(参见 MyIterator,你永远不能通过 "AM" 找到之前的数据 "I")
什么叫可动态生成的呢?我们以一个例子为例
import random
class Random:
def __iter__(self):
return self
def __next__(self):
return random.random()
for i in Random():
print(i)这个程序不会自己停下来!因为它一直在实时的动态生成数据,而且不占用内存空间!(这实际上就是我们接下来要讨论的
Generator)
生成器(Generator)
一个函数在任意地方出现了 yield 关键词,无论是否会被执行,该函数都会变异成为 Generator
def my_generator_function():
return 0
yield "HI"
my_generator = my_generator_function()
print(my_generator)
# <generator object my_generator at 0x7f169b38c2e0>
在 Python 官方文档中,把变异的函数称为 Generator,而其返回的对象叫做 Generator Iterator,尽管我们并不喜欢这么说。
我们更喜欢将函数称为
Generator Function而返回的对象称为Generator
而通过这个名字我们也可以看出来,事实上 Generator Iterator 也是迭代器。
assert my_generator is iter(my_generator)
assert hasattr(my_generator, "__next__") and hasattr(my_generator, "__iter__")
也就是说,Generator 实际上只是一个函数版本的 Iterator,唯一的不同是 next(Generator) 是由 yield 来控制的。
接下来我们重点关注 yield 这个表达式
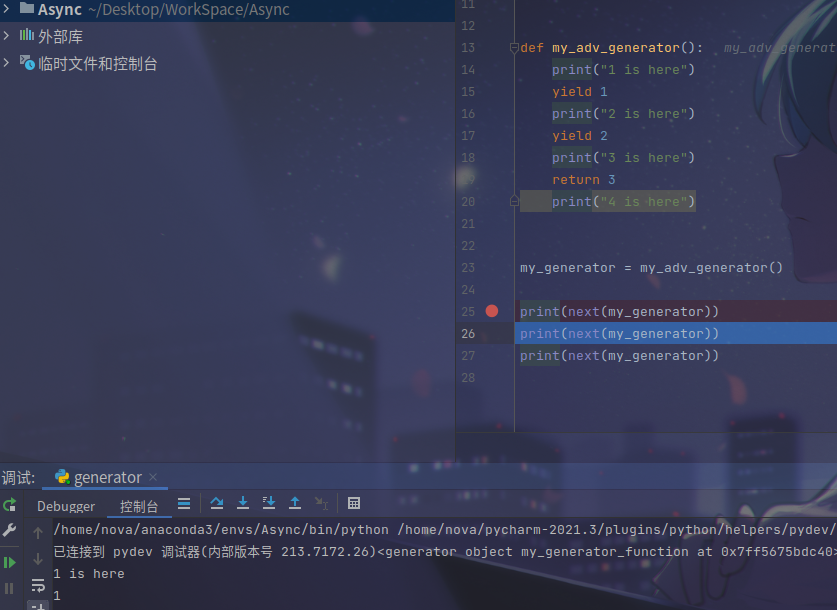
从图中我们可以发现,第一次执行 next(my_generator) 时,函数执行到了 yield 1 便被 挂起,等到下一次的 next(my_generator) 后才会��执行接下来的代码块。
为了更清楚的看出这个特点,我们实现一个 Generator 的计数器作为例子(代码复制于 itertools)
def count(start: int = 0, step: int = 1):
while True:
yield start
start += step
在第一次 __next__ 执行时,直接 yield start
此后,每次执行都会先执行 yield 下面的代码块 start += step,并重新执行循环,再次 yield start
我们继续来看一开始的例子。
在遇到 return 后,next(my_generator) 则直接抛出了 StopIteration 的异常(且 StopIteration.value 就是我们 return 的值),且 return 之后的代码块不再执行(哪怕你处理了 #line:28 的错误执行到了 #line:29 也仍会抛出 StopIteration)
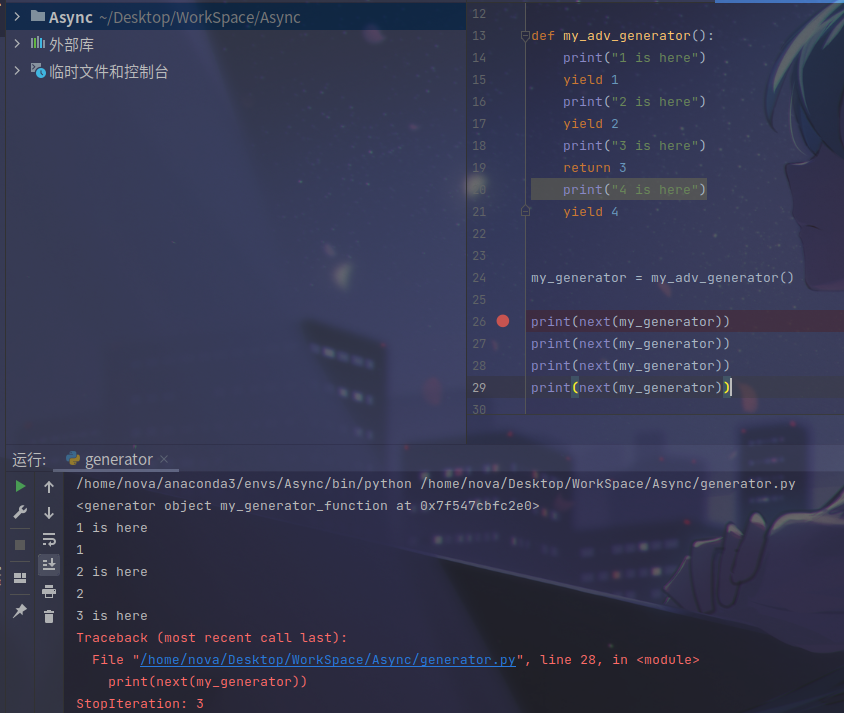
此时,我们可以将我们的 MyIterator 对象重写成 Generator 形式
class MyIterator:
def __init__(self, Iter):
self.index = 0
self.data = Iter
def __iter__(self):
idx = 0
while idx < len(self.data):
yield self.data[idx]
idx += 1
things = ["I", "AM", "ITERABLE", "GOD"]
ge = MyIterator(things)
for i in ge: # 需要注意的是, `ge` 本身并非迭代器, 只有 `iter(ge)` 返回的 `generator` 对象才是迭代器
# 换句话说,`Generator` 自动帮我们实现了 `__iter__` 接口,而 `__next__` 就是我们的 `yield`
print(i)
为什么讲迭代器
为何我们在说协程之前要需要先讲迭代器呢?这就涉及到我们的 Function 和 Generator 的底层运行原理。
代码对象
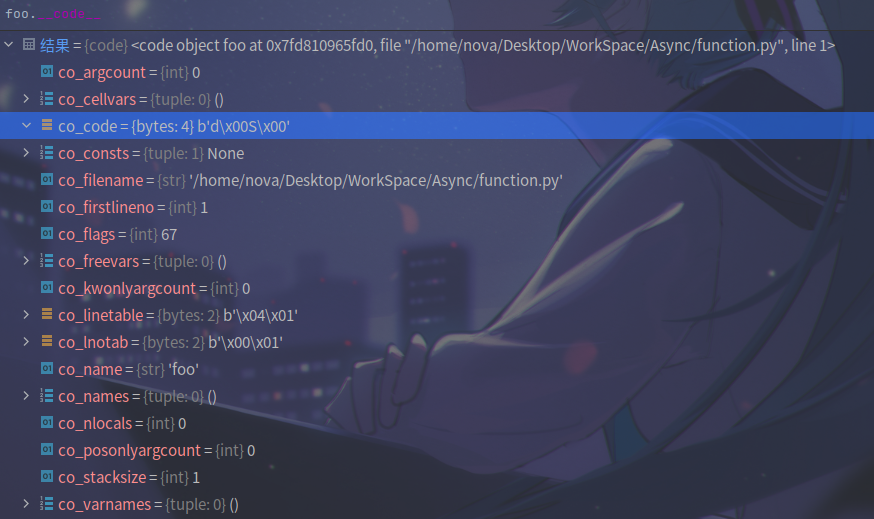
def foo():
...
print(foo.__code__)
如上的代码打印了 foo() 函数的代码对象,代码对象保存了函数的一些静态信息。
帧对象
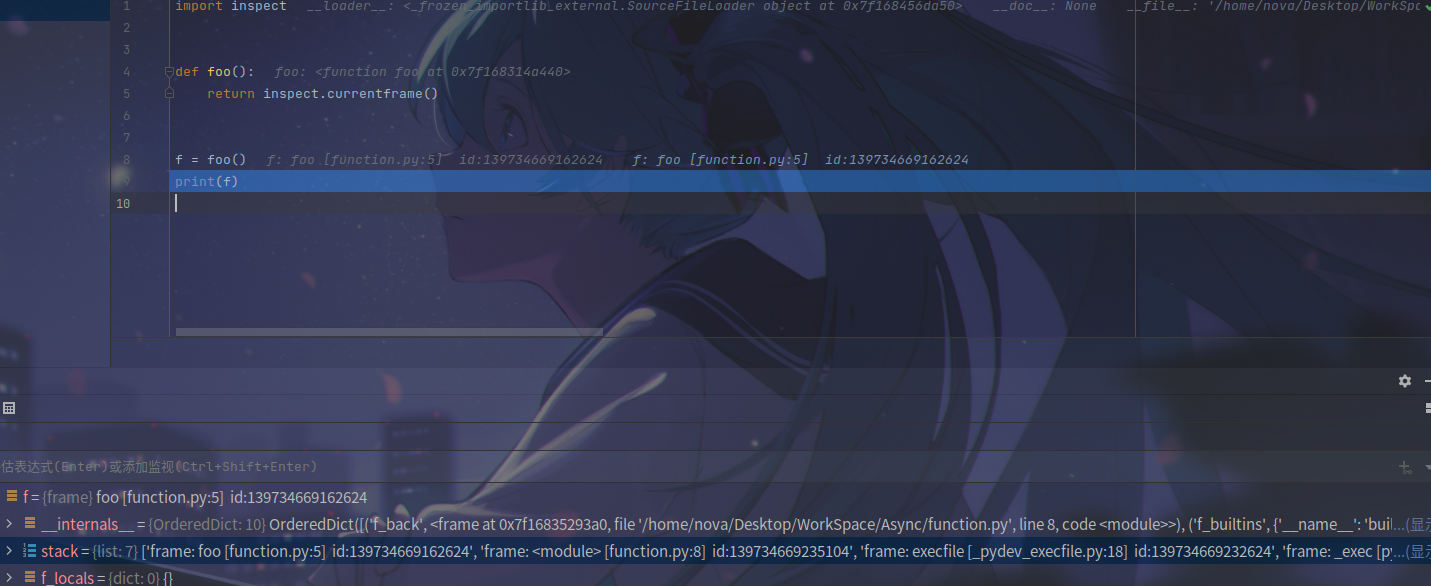
使用 inspect 返回当前 frame,需要注意的是一般情况下函数运行完毕 frame 就会自动销毁,因此我们使用变量保存。
可以看到,frame 保存了函数运行时的一些状态,其中就有我们特别要关注的 stack
你可以预想到的,正常的函数执行是一个 先进后出 的 栈 结构,在这里不做进一步的解释。(详情请去看 C 语言函数调用栈)
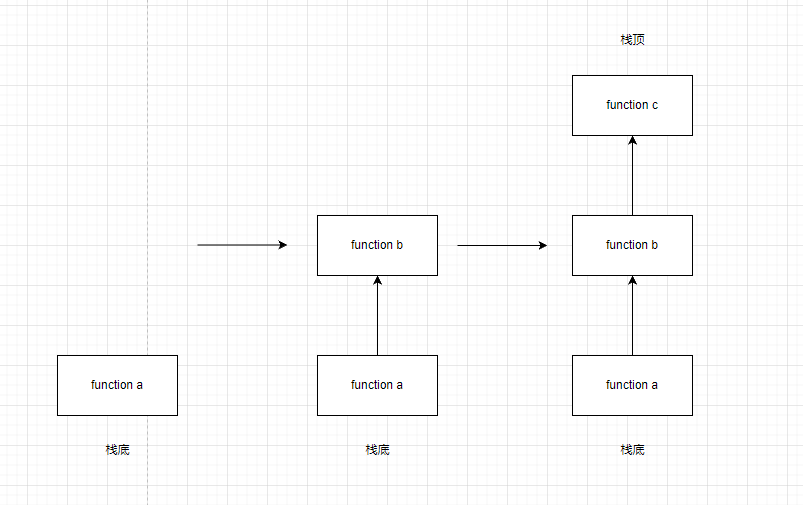
而 Generator 不同,它自带了一个帧,每次调用 __next__ 时都会使用这个帧。换句话说,每次这个帧都会执行出栈入栈操作。
而这个帧的入栈时机就是 next() 执行的时刻,出栈就是 next() 返回的时刻。
直到抛出 StopIteration,这个帧就会被销毁。
def generator():
...
yield ...
def a():
m = generator()
b(m)
c(m)
def b(g):
return next(g)
def c(g):
return next(g)
a()
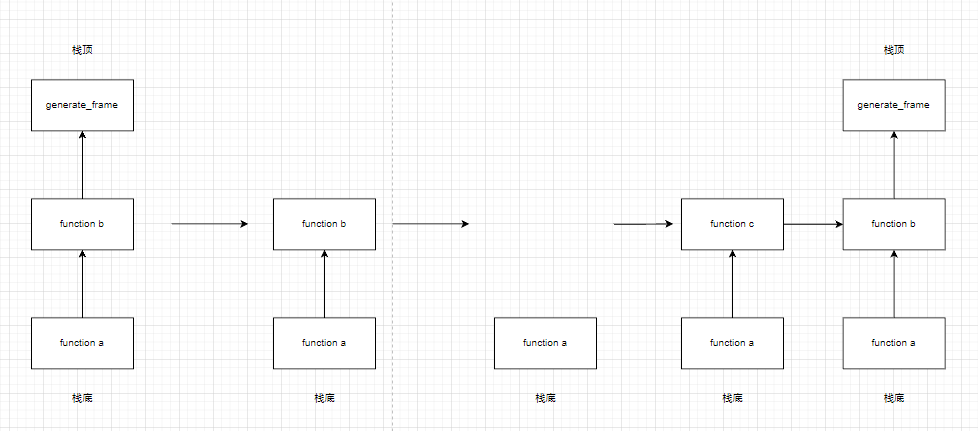
这部分可能有点难理解,推荐是用自己下断点调一调啃一下。
同步和异步
此时,聪明的你可能已经想到了为什么我们要讨论生成器
如果是一个普通的函数
def normal_func():
foo()
bar()
根据栈结构,你永远不可能在 foo() 执行完成前执行 bar()
而如果是一个生成器
def generator_func_1():
...
yield # step1
...
yield # step2
...
yield # step3
def generator_func_2():
...
yield # step1
...
yield # step2
...
yield # step3
tasks = []
a = generator_func_1()
b = generator_func_2()
tasks.extend([a, b])
def runner():
for task in tasks:
next(task)
借助 runner() 的多次运行,我们可以同时的运行多个任务(在例子里,a 和 b)
每次 yield 之前的代码就是我们每一次的业务逻辑,每次 yield 完都会把控制权让出来交由下一个任务,这就是 协作 的概念
换而言之,
对于迭代器,我们关注的重点是
yield返回的数据对于协程,我们关注的重点是**
yield前执行的业务代码**
深入浅出 yield from
yield 表达式
之前在 生成器(Generator) 那里提到过一嘴,其实 yield 是一个表达式(Expression),这意味着它可以进行赋值等的操作。
my_yield = yield
my_yield = yield + 1
generator.send()
既然他可以被赋值,那我们不妨来看看它的值是多少
def _yield():
my_yield = yield
print(my_yield)
g = _yield()
next(g) # 1
next(g) # 2
根据上面所说的内容,我们的函数是执行到 yield 时就被挂起的,因此,想要 print 执行的话,还得再进行一次迭代。此时由于函数返回了隐式的 None,所以程序还会抛出 StopIteration 异常。这个结果是显而易见的。
next 作为最初期的生成器语法,到目前版本只是作为一个兼容使用(初期的生成器里,yield 是一个关键字,无法被赋值),在 Python >= 3.5 的版本后,针对生成器添加了一个新的方法,generator.send(),它接受一个参数,作用是在恢复挂起生成器的同时,将值�传入 yield 表达式
在这个例子里
g.send(1) # 2
# 相当于
next(g) # 2
def _yield()
my_yield = 1
print(my_yield)
不过值得注意的是,在生成器未运行时,第一个 generator.send() 的参数必须是 None,否则它会抛出一个 TypeError,这是显然的,因为你无法在一个刚运行的生成器里找到一个可赋值的 yield
g.send(1) # 1
# TypeError: can't send non-None value to a just-started generator
优先级
此外,在使用 yield 表达式时,它的优先级也是我们需要注意的。
def _yield():
my_yield = yield + 1
print(my_yield)
g = _yield()
print(g.send(None))
g.send(1)
"""
1
1
"""
yield 仍会保留其作为 yield 的特性,即 返回 yield 后的语句
也就是说,当我们执行�第一次 g.send(None) 时,yield 会返回 + 1 这个表达式
第二次执行 g.send(1) 时,它会把 yield + 1 这个表达式都替换成 1 (因为后面的 + 1 这个表达式已经返回了)
因此,我们 print(my_yield) 的预期结果是 2,而其实最后是 1。
解决方法也很简单,只需要通过括号手动设置优先级即可
def _yield():
my_yield = (yield) + 1
print(my_yield)
g = _yield()
print(g.send(None))
g.send(1)
"""
None
2
"""
generator.close() 和 generator.throw()
没什么好说的,close增加了一个方法让我们人为可控的结束 generator ,throw 则增加了一个方法让我们向 generator 内部抛出异常。它们会向生成器内部对应的 yield (与 generator.send() 同样的 yield 表达式)抛出一个 GeneratorExit / 自定义的异常,可以用于执行一些资源释放等的工作。
除了显式调用 generator.close() 外,在 Python 执行隐式的内存释放(del, 程序退出等等)的时候,也��会调用这个 close 方法
最后,我们通过一个例子来体会一哈 yield 表达式的作用
def calc_average():
""" 计算动态数据的平均值 """
total = 0
count = 0
average = 0
while True:
try:
val = yield average
except GeneratorExit:
return average
else:
total += val
count += 1
average = total / count
g = calc_average()
g.send(None) # 0
g.send(1) # 1.0
g.send(9) # 5.0
...
yield from
RESULT = yield from EXPR # EXPR must be Iterable
# 等价于(省略了部分代码好针对协程)
_i = iter(EXPR)
try:
_y = _i.send(None) # Prime, 预激
except StopIteration as _e:
_r = _e.value # 没有碰到 yield, 直接返回
else:
while True:
try:
_s = yield _y # 把结果原样 yield 出去,并接收传入的值
except GeneratorExit as _e:
_i.close() # 关闭 _i
raise _e # 再次抛出异常
except BaseException as _e:
_x = sys.exe_info()
try:
_y = _i.throw(*_x) # 向 _i 中抛出相同的异常
except StopIteration as _e:
_r = _e.value
break
else:
_y = _i.send(_s) # 再把接受的值原样 send 出去
except StopIteration as _e:
_r = _e.value
break
RESULT = _r # 最后的结果
而在协程里,事实上我们并不会传入值(也就是 _s = yield _y 永远是 None)
因此,我们还可以再简化为:
_i = iter(EXPR)
while True:
try:
_y = _i.send(None)
except StopIteration as _e:
_r = _e.value
else:
try:
yield _y # 把结果原样 yield 出去
except GeneratorExit as _e:
_i.close() # 关闭 _i
raise _e # 再次抛出异常
except BaseException as _e:
_x = sys.exe_info()
try:
_y = _i.throw(*_x) # 向 _i 中抛出相同的异常
except StopIteration as _e:
_r = _e.value
break
RESULT = _r # 最后的结果
你可以发现,这个 yield from 不过是一个套娃的过程。
真正的 AsyncIO
为什么要引入这个关键字呢?其实这就是协程,或者说异步的本质:
不能消除阻塞,而是将阻塞从下游传到上游
函数协程化
from time import sleep
def task():
""" 新建一个 task """
print("TASK BEGIN...")
print(" MainStep...")
main_result = main_step()
print(f" MainStep Finished with result {main_result}")
print("TASK END")
def main_step():
print(" SmallStep(s)...")
small_result = small_step()
... # There could be more steps
print(f" SmallStep(s) Finished with result {small_result}")
return small_result * 100
def small_step():
print(" I'm doing the small step...")
sleep(2) # doing something...
print(" I'm finished")
return 123
task()
让我们来看这样一段代码。可以看到,我们的 sleep (也就是实际事件中的阻塞,例如网络请求或是其他的可能导致阻塞的 IO 操作)实际是发生在 small_step 内部的,倘若我们 main_step() 中有不止一个的 small_step ,那么其他的小步骤一定要等到我们定义的这个 small_step 结束后才会执行。
我们不妨这样把阻塞转移到 main_step()
def small_step():
print(" I'm doing the small step...")
t1 = time.time()
yield sleep, 2
assert time.time() - t1 > 2, "你没阻塞,小猪"
print(" I'm finished")
return 123
此时,我们返回的内容不再是直接的结果,而是一个协程。
因此我们对 main_step() 也需要做一定的改动
def main_step():
print(" SmallStep(s)...")
small_coro = small_step()
while True:
try:
x = small_coro.send(None)
except StopIteration as _e:
small_result = _e.value
break
else: # 阻塞
yield x # 再次传到上游
... # There could be more steps
print(f" SmallStep(s) Finished with result {small_result}")
return small_result * 100
同样的,我们对于 one_task() 也这样的作出改动
def task():
""" 新建一个 task """
print("TASK BEGIN...")
print(" MainStep...")
main_coro = main_step()
while True:
try:
x = main_coro.send(None)
except StopIteration as _e:
main_result = _e.value
break
else:
func, arg = x
func(arg)
print(f" MainStep Finished with result {main_result}")
print("TASK END")
细心的人可能已经发现了,我们的 yield 是传染性的,也就是说你在 small_step 里利用了 yield,那么对于它的上游函数,也必须要修改(这也正是 async 的工作模式)
此时我们回到 main_step,对照 yield from 的等价代码其实你就明白了,这个关键词的存在意义就是用于简化我们套娃(或者官方一点,透传)的过程。
def main_step():
print(" SmallStep(s)...")
small_result = yield from small_step()
print(f" SmallStep(s) Finished with result {small_result}")
return small_result * 100
如果我们把
yield from改成await呢?如果你想到了这个,证明你已经理解了async的原理。
然而这样做,我们就会混用 yield from 和 yield 两种方法。有没有方法统一我们的 task, main_step, small_step 呢?
def small_step():
print(" I'm doing the small step...")
t1 = time.time()
yield from sleep, 2
assert time.time() - t1 > 2, "你没阻塞,小猪"
print(" I'm finished")
return 123
我们直接把 small_step() 里的 yield 改成 yield from,现在,如果你还记得 yield from 的等价代码,你就知道我们应该传入一个 Iterable。
我们定义一个新的类来包裹它。
def small_step():
print(" I'm doing the small step...")
t1 = time.time()
yield from YieldIterable(sleep, 2)
assert time.time() - t1 > 2, "你没阻塞,小猪"
print(" I'm finished")
return 123
class YieldIterable:
def __init__(self, *obj):
self.obj = obj
def __iter__(self):
yield self.obj
此时,我们的 small_step 和 main_step 都已经 协程化 ,只剩下一个 task。对比代码我们可以发现,事实上我们的 task 内的代码已经很接近 yield from 的形式。
def task():
""" 新建一个 task """
print("TASK BEGIN...")
print(" MainStep...")
main_result = yield from main_step()
print(f" MainStep Finished with result {main_result}")
print("TASK END")
由于我们的 task 出现了 yield,因此我们无法直接的运行 task()
任务驱动器
我们可以通过一个任务驱动器来运行它。
class Task:
def __init__(self, _task):
self.coro = _task
def run(self):
while True:
try:
x = self.coro.send(None)
except StopIteration as _e:
result = _e.value
break
else:
func, arg = x
func(arg)
return result
Task(task()).run()
此时,我们的协程改造已经结束了。事实上,我们完全可以修改我们的 yield from 为 await,并添加 async 关键字,同时把我们类中的 __iter__ 改为 __await__,接下来,我们也将在这个的基础上继续完善。
import time
from time import sleep
async def task():
""" 新建一个 task """
print("TASK BEGIN...")
print(" MainStep...")
main_result = await main_step()
print(f" MainStep Finished with result {main_result}")
print("TASK END")
async def main_step():
print(" SmallStep(s)...")
small_result = await small_step()
print(f" SmallStep(s) Finished with result {small_result}")
return small_result * 100
async def small_step():
print(" I'm doing the small step...")
t1 = time.time()
await Awaitable(sleep, 2)
assert time.time() - t1 > 2, "你没阻塞,小猪"
print(" I'm finished")
return 123
class Awaitable:
def __init__(self, *obj):
self.obj = obj
def __await__(self):
yield self.obj
class Task:
def __init__(self, _task):
self.coro = _task
def run(self):
while True:
try:
x = self.coro.send(None)
except StopIteration as _e:
result = _e.value
break
else:
func, arg = x
func(arg)
return result
Task(task()).run()
回到我们的 small_step,我们的阻塞使用的是 sleep, 2 这么一个硬编码的阻塞,而现实中的阻塞远不止这么一种,我们应该追求一种更为普遍的阻塞处理。
在 Awaitable 里,我们直接 yield self。
class Awaitable:
def __init__(self, *obj):
self.obj = obj
def __await__(self):
yield self
class Task:
def __init__(self, _task):
self.coro = _task
def run(self):
while True:
try:
x = self.coro.send(None)
except StopIteration as _e:
result = _e.value
break
else:
func, arg = x.obj
func(arg)
return result
现在,注意到一件事:我们的 Task.run() 仍然是阻塞的,我们的程序的运行权仍然没有彻底的让出去。让我们继续来修改 Task 的代码。
class Task:
def __init__(self, _task):
self.coro = _task
self._done = False
self._result = None
def run(self):
if not self._done:
try:
x = self.coro.send(None)
except StopIteration as _e:
self._result = _e.value
self._done = True
else:
... # 这不应该出现, 应该抛出异常
t = Task(task())
t.run()
for i in range(10): # 在 sleep(2) 的过程中,我们可以做其他的事情。
print("doing something", i)
sleep(0.2)
t.run()
我们手工调度了多任务,在实际上,我们应该通过事件循环(Event Loop)自动的调度任务
Event Loop
首先,任务必定需要有一个队列。我们使用 deque 这个双向队列来保存。
class Event:
def __init__(self):
self._queue = collections.deque()
def call_soon(self, callback, *args, **kwargs):
self._queue.append((callback, args, kwargs))
接下来我们添加定时任务。由于定时任务的特殊性,我们使用 堆 来储存。这里,利用 heapq 来操作。
class Event:
def __init__(self):
self._queue = collections.deque()
self._scheduled = []
def call_soon(self, callback, *args, **kwargs):
self._queue.append((callback, args, kwargs))
def call_later(self, delay, callback, *args, **kwargs):
_t = time.time() + delay
heapq.heappush(self._scheduled, (_t, callback, args, kwargs))
接着我们写事件调度的函数。
class Event:
def __init__(self):
self._queue = collections.deque()
self._scheduled = []
self._stopping = False
def call_soon(self, callback, *args, **kwargs):
self._queue.append((callback, args, kwargs))
def call_later(self, delay, callback, *args, **kwargs):
_t = time.time() + delay
heapq.heappush(self._scheduled, (_t, callback, args, kwargs))
def stop(self):
self._stopping = True
def run_forever(self):
while True:
self.run_once() # 至少要执行一次, 所以把判断写在下面
if self._stopping:
break
def run_once(self):
now = time.time()
if self._scheduled and now > self._scheduled[0][0]:
_, cb, args, kwargs = heapq.heappop(self._scheduled)
self._queue.append((cb, args, kwargs))
task_num = len(self._queue) # 防止运行过程中队列添加更多任务
for _ in range(task_num):
cb, args, kwargs = self._queue.popleft()
cb(*args, **kwargs)
t = Task(task())
loop = Event()
loop.call_soon(t.run)
loop.call_later(2, t.run)
loop.call_later(2.1, loop.stop)
loop.run_forever()
现在,我们修改一下 small_step
async def small_step():
t1 = time.time()
time_ = random.randint(1, 3)
await Awaitable(time_)
assert time.time() - t1 > time_, "你没阻塞,小猪"
return time_
此时,由于这个时间传到了 Task,所以我们要在 Task 中处理,换而言之就是在阻塞的时候添加一个 loop.call_later(),回调就是 self.run
class Task:
def __init__(self, _task):
self.coro = _task
self._done = False
self._result = None
def run(self):
if not self._done:
try:
x = self.coro.send(None)
except StopIteration as _e:
self._result = _e.value
self._done = True
else:
loop.call_later(*x.obj, self.run)
else:
... # 这不应该出现, 应该抛出异常
我们便可以删除我们手动指定的 call_later 了
t = Task(task())
loop = Event()
loop.call_soon(t.run)
loop.call_later(1.1, loop.stop) # random() 只会出现 0 ~ 1 之间的
loop.run_forever()
现在,我们试试多任务实现,并通过一些参数来实际的展示 异步 的效果。
import collections
import heapq
import itertools
import random
import time
from time import sleep
count = itertools.count(0)
total = 0
async def task():
""" 新建一个 task """
print("TASK BEGIN...")
print(" MainStep...")
main_result = await main_step()
print(f" MainStep Finished with result {main_result}")
print("TASK END")
async def main_step():
print(" SmallStep(s)...")
small_result = await small_step()
print(f" SmallStep(s) Finished with result {small_result}")
return small_result * 100
async def small_step():
t1 = time.time()
time_ = random.random()
await Awaitable(time_)
assert time.time() - t1 > time_, f"{time_} 你没阻塞,小猪 {time.time() - t1}"
return time_
class Awaitable:
def __init__(self, *obj):
self.obj = obj
def __await__(self):
yield self
class Task:
def __init__(self, _task):
self.coro = _task
self._done = False
self._result = None
self._id = f"Task-{next(count)}"
def run(self):
print(f"--------- {self._id} --------")
if not self._done:
try:
x = self.coro.send(None)
except StopIteration as _e:
self._result = _e.value
self._done = True
else:
loop.call_later(*x.obj, self.run)
else:
... # 这不应该出现, 应该抛出异常
print("-------------------------")
class Event:
def __init__(self):
self._queue = collections.deque()
self._scheduled = []
self._stopping = False
def call_soon(self, callback, *args, **kwargs):
self._queue.append((callback, args, kwargs))
def call_later(self, delay, callback, *args, **kwargs):
_t = time.time() + delay
global total
total += delay
heapq.heappush(self._scheduled, (_t, callback, args, kwargs))
def stop(self):
self._stopping = True
def run_forever(self):
while True:
self.run_once() # 至少要执行一次, 所以把判断写在下面
if self._stopping:
break
def run_once(self):
now = time.time()
if self._scheduled and now > self._scheduled[0][0] + (10 ** -5):
_, cb, args, kwargs = heapq.heappop(self._scheduled)
self._queue.append((cb, args, kwargs))
task_num = len(self._queue) # 防止运行过程中队列添加更多任务
for _ in range(task_num):
cb, args, kwargs = self._queue.popleft()
cb(*args, **kwargs)
loop = Event()
for _ in range(1000):
t = Task(task())
loop.call_soon(t.run)
loop.call_later(1.1, loop.stop)
t1 = time.time()
loop.run_forever()
print(f"actually: {time.time()-t1}")
print(f"total: {total}")
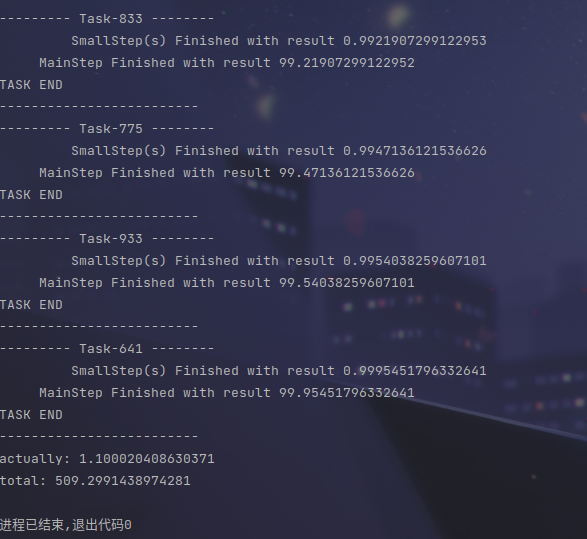
可以看到,我们正常运行这么多任务需要的时间应该是 509.3s,但是由于多任务的调度实现的并发执行,我们实际上在 1s 以内便运行完成了这所有的 1000 个任务。
Future
最后,我们的代码是主动使用 sleep 来模拟阻塞的,那实际情况我们应该怎么做呢?
通常情况下,我们是希望我们执行某个操作,并且获得某个值,例如下面
async def small_step():
result = await Awaitable(...)
return result
此时我们应该引入 Future。什么叫 Future?就是未来才会发生的结果,对比 Awaitable,我们显然不能在创建时就将结果直接传入。
class Future:
def __init__(self):
self._result = None
self._done = False
def set_result(self, result):
if self._done:
raise RuntimeError() # 不允许的操作
self._result = result
self._done = True
@property
def result(self):
if self._done:
return self._result
raise RuntimeError()
def __await__(self):
yield self
这样做的话,我们必须要有一个东西来指派什么时候运行 set_result
async def small_step():
fut = Future()
# do something, 它会调用 set_result
...
result = await fut
return result
此时,Task 中接收到了我们这个 future,但是这个 future 中什么信息都没有,只有一个标志位告诉我们任务还没完成。
我们的 Task 中应该如何知道它什么时候恢复运行呢?
我们可以在 Future 中再添加一个 callback 的记录。
class Future:
def __init__(self):
self._result = None
self._done = False
self._callbacks = []
def add_done_callback(self, cb):
self._callbacks.append(cb)
def set_result(self, result):
if self._done:
raise RuntimeError() # 不允许的操作
self._result = result
self._done = True
for cb in self._callbacks:
cb() # 当然可能有其他参数
@property
def result(self):
if self._done:
return self._result
raise RuntimeError()
def __await__(self):
yield self
return self.result # result = await fut 会获取这个值
class Task:
def __init__(self, _task):
self.coro = _task
self._done = False
self._result = None
self._id = f"Task-{next(count)}"
def run(self):
print(f"--------- {self._id} --------")
if not self._done:
try:
x = self.coro.send(None)
except StopIteration as _e:
self._result = _e.value
self._done = True
else:
x.add_done_callback(self.run)
else:
... # 这不应该出现, 应该抛出异常
print("-------------------------")
现在,我们通过写一个 fake_io 来查看效果
def fake_io(fut):
def read():
sleep(random.random()) # IO 阻塞
fut.set_result(random.random())
threading.Thread(target=read).start()
最后,我们观察 Task 及 Future
我们可以发现 Task 完全可以继承 Future
class Task(Future):
def __init__(self, _task):
super().__init__()
self.coro = _task
self._id = f"Task-{next(count)}"
def run(self):
print(f"--------- {self._id} --------")
if not self._done:
try:
x = self.coro.send(None)
except StopIteration as _e:
self.set_result(_e.value)
else:
x.add_done_callback(self.run)
else:
... # 这不应该出现, 应该抛出异常
print("-------------------------")
此时,AsyncIO 已经��基本实现了。当然,相比 Python 本身的 AsyncIO,我们的代码可以叫做十分简陋。性能不够(毕竟不是 C 写的)之外,也在更多的异常处理等等方面存在问题。最后放一下优化后的代码。( Task 与 loop 挂钩的方面没说明但是写了)
import collections
import heapq
import itertools
import random
import threading
import time
from time import sleep
count = itertools.count(0)
blocked = 0
async def task():
""" 新建一个 task """
print("TASK BEGIN...")
print(" MainStep...")
main_result = await main_step()
print(f" MainStep Finished with result {main_result}")
print("TASK END")
async def main_step():
print(" SmallStep(s)...")
small_result = await small_step()
print(f" SmallStep(s) Finished with result {small_result}")
return small_result * 100
async def small_step():
fut = Future()
fake_io(fut)
result = await fut
return result
class Future:
def __init__(self):
self._result = None
self._done = False
self._callbacks = []
def add_done_callback(self, cb):
self._callbacks.append(cb)
def set_result(self, result):
if self._done:
raise RuntimeError() # 不允许的操作
self._result = result
self._done = True
for cb in self._callbacks:
cb() # 当然可能有其他参数
@property
def result(self):
if self._done:
return self._result
raise RuntimeError()
def __await__(self):
yield self
return self.result
class Task(Future):
def __init__(self, _task):
super().__init__()
self._loop = loop
self.coro = _task
self._id = f"Task-{next(count)}"
self._loop.call_soon(self.run)
self._start_time = time.time()
def run(self):
print(f"--------- {self._id} --------")
if not self._done:
try:
x = self.coro.send(None)
except StopIteration as _e:
self.set_result(_e.value)
global blocked
blocked += time.time() - self._start_time
else:
x.add_done_callback(self.run)
else:
... # 这不应该出现, 应该抛出异常
print("-------------------------")
class Event:
def __init__(self):
self._queue = collections.deque()
self._scheduled = []
self._stopping = False
def call_soon(self, callback, *args, **kwargs):
self._queue.append((callback, args, kwargs))
def call_later(self, delay, callback, *args, **kwargs):
_t = time.time() + delay
heapq.heappush(self._scheduled, (_t, callback, args, kwargs))
def stop(self):
self._stopping = True
def run_forever(self):
while True:
self.run_once() # 至少要执行一次, 所以把判断写在下面
if self._stopping:
break
def run_once(self):
now = time.time()
if self._scheduled and now > self._scheduled[0][0] + (10 ** -5):
_, cb, args, kwargs = heapq.heappop(self._scheduled)
self._queue.append((cb, args, kwargs))
task_num = len(self._queue) # 防止运行过程中队列添加更多任务
for _ in range(task_num):
cb, args, kwargs = self._queue.popleft()
cb(*args, **kwargs)
def fake_io(fut):
def read():
sleep(t_ := random.random()) # IO 阻塞
fut.set_result(t_)
threading.Thread(target=read).start()
def run_until_all_task(tasks):
if tasks := [_task for _task in tasks if not _task._done]:
loop.call_soon(run_until_all_task, tasks)
else:
loop.call_soon(loop.stop)
loop = Event()
all_tasks = [Task(task()) for _ in range(1000)]
loop.call_soon(run_until_all_task, all_tasks)
t1 = time.time()
loop.run_forever()
print(time.time() - t1, blocked)